
September 16, 2024
On September 12, OpenAI ("OAI") released o1-Preview, the most consequential model since at least GPT-4's debut in February 2023. The results showcased o1's power, yet there has been a surge of misguided commentary from supposedly informed individuals. Let's develop a framework to better contextualize this release.

The algorithmic breakthrough of o1 is largely based on a research paper from May 2023. Essentially, o1-Preview formulates a plan for the steps needed to solve a problem, executes each step, and then provides an answer.
This accomplishment took 20 of the smartest people working on it roughly a year to get right, so there was surely thorough optimization, although the team seems to think there is substantial room for continued improvement.
Yes, for the most part. For example, my company employs sophisticated agentic flows and CoTs to derive answers. However, we haven't had the capacity to spend virtually unlimited time on each API call, making each one extremely thorough, iterative, or recursive. We've substituted o1-Preview into some of the most critical steps and observed a meaningful increase in output quality.
Theoretically, we could have replicated the exact CoTs that o1-Preview uses when facing a problem and achieved similar results. It would be relatively easier for us because we don't need to generalize the reasoning and can leverage our subject matter expertise. However, across an app with hundreds of API calls, this isn't realistic.
Furthermore, o1-Preview seems to have more pre-training information. As a result, when posing a sophisticated state law hypothetical, GPT-4o often hallucinates cases, while Claude 3.5 Sonnet rarely hallucinates but provides non-controlling case law. In contrast, o1-Preview excels at minimizing hallucinations and, when properly prompted, provides relevant cases from the appropriate jurisdiction.
That said, this update wasn't as impactful for our application compared to what we'd expect from a similar rise in intelligence via non-CoT approaches. Additionally, the slowness is a drawback for broad usage. Our plan is to integrate o1-Preview into the most complex and critical API calls throughout our app and include backups in case it fails.
o1-Preview is very much in its preliminary stage. It lacks JSON support, streaming, internet searches within ChatGPT (although we can circumvent this with SerpAPI), system messages, multi-modality, attachments, and a high rate limit. These issues will likely be addressed when the full version of o1 is released.
From a vibes standpoint, the negative commentary has been more widespread than warranted and generally lacks solid support. Pessimists see a new model, find some simple problem that occasionally trips it up, and then declare there's no progress, that OAI is a sham, or that AGI is very far off. This is a flawed method for analyzing progress and extrapolating AGI timelines.
For example, Gary Marcus has famously predicted that while there would be many GPT-4-level models available by the end of 2024, there would be no meaningful jump in capabilities beyond that level. This is objectively incorrect based on o1-Preview's performance. It will become even more apparent when the full version of o1 is released, and if Orion arrives earlier than expected, his prediction will look particularly misguided.
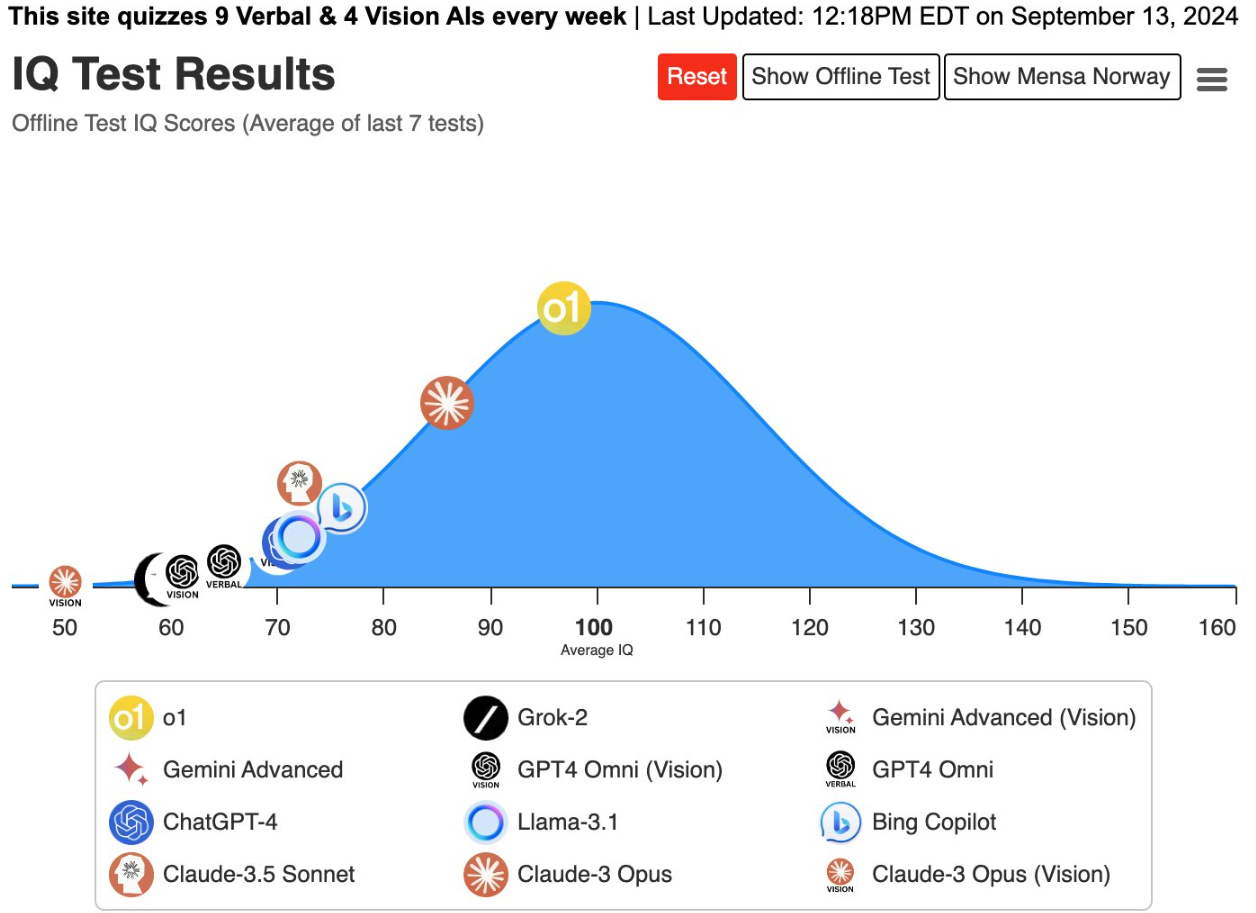
A reasonable approach is to establish comprehensive benchmarks and analyze progress over time. While traditional benchmarks can be gamed, groups like LiveBench have overcome these challenges.
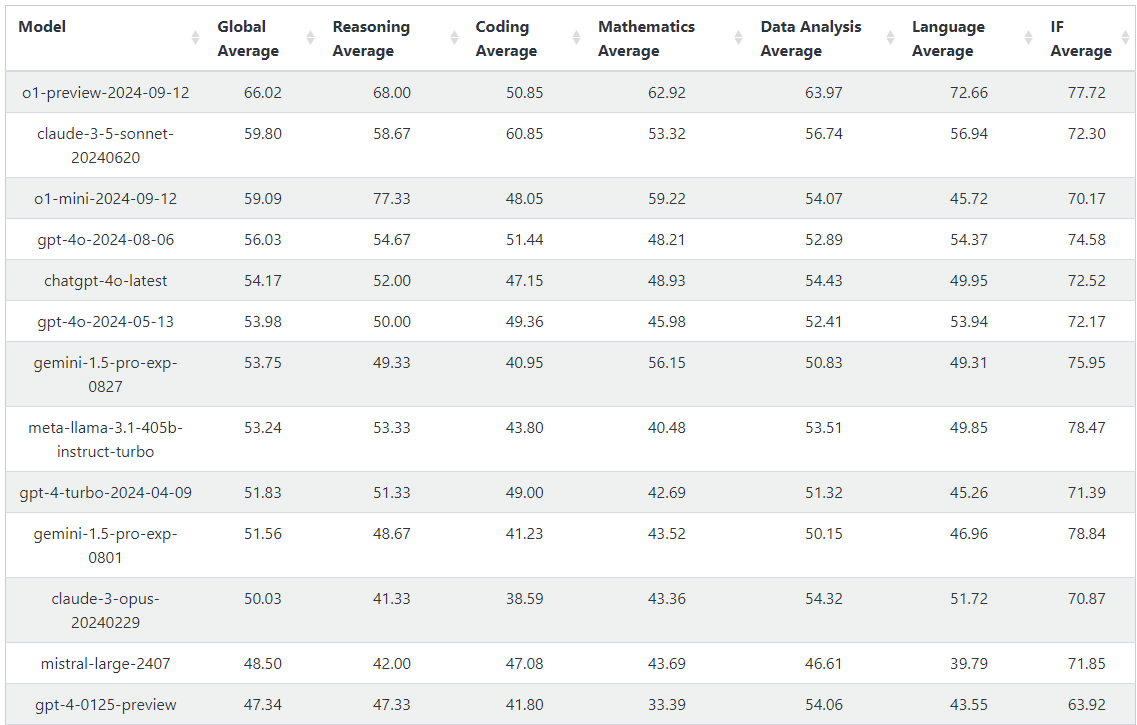
Note: GPT-3.5-Turbo scored 33.21 for global average. Thus, o1-Preview is a bigger jump from GPT-4-0125 (+19) than the jump from GPT-3.5 to GPT-4 (+14), and o1 "full" will show a significant further increase.
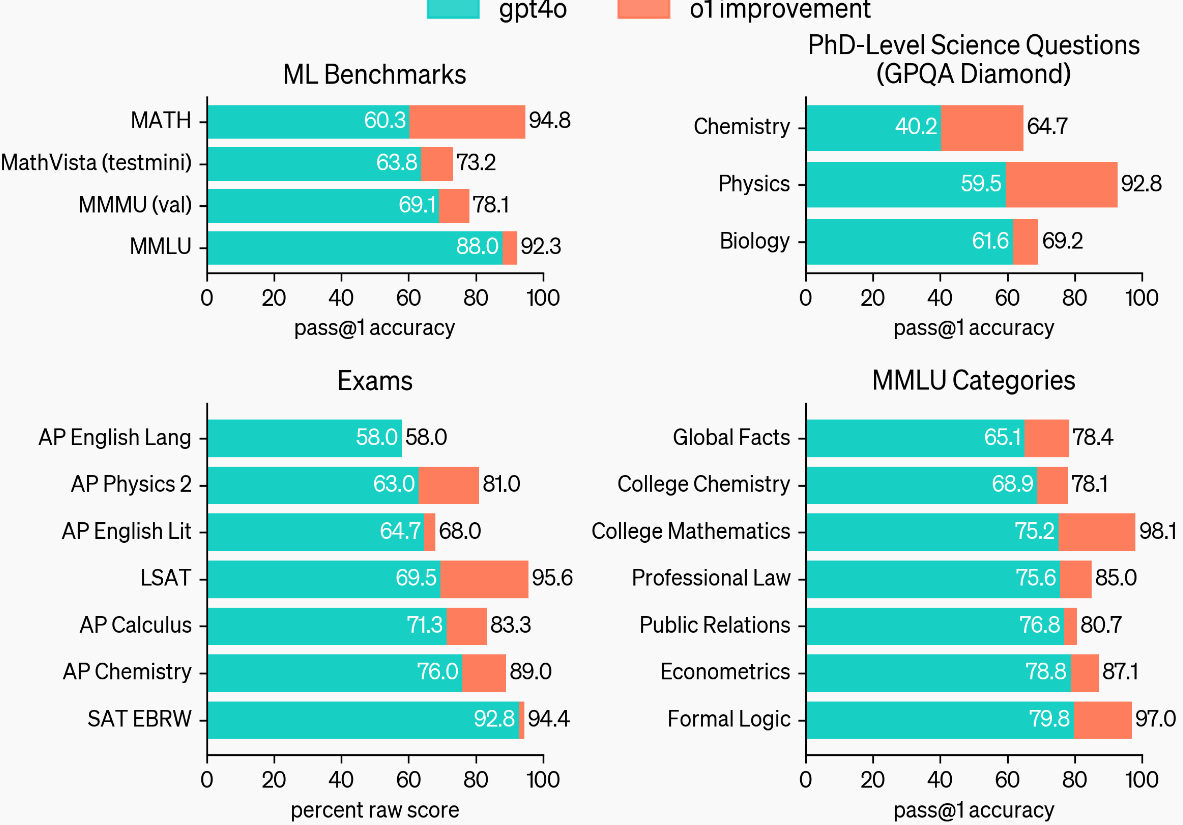
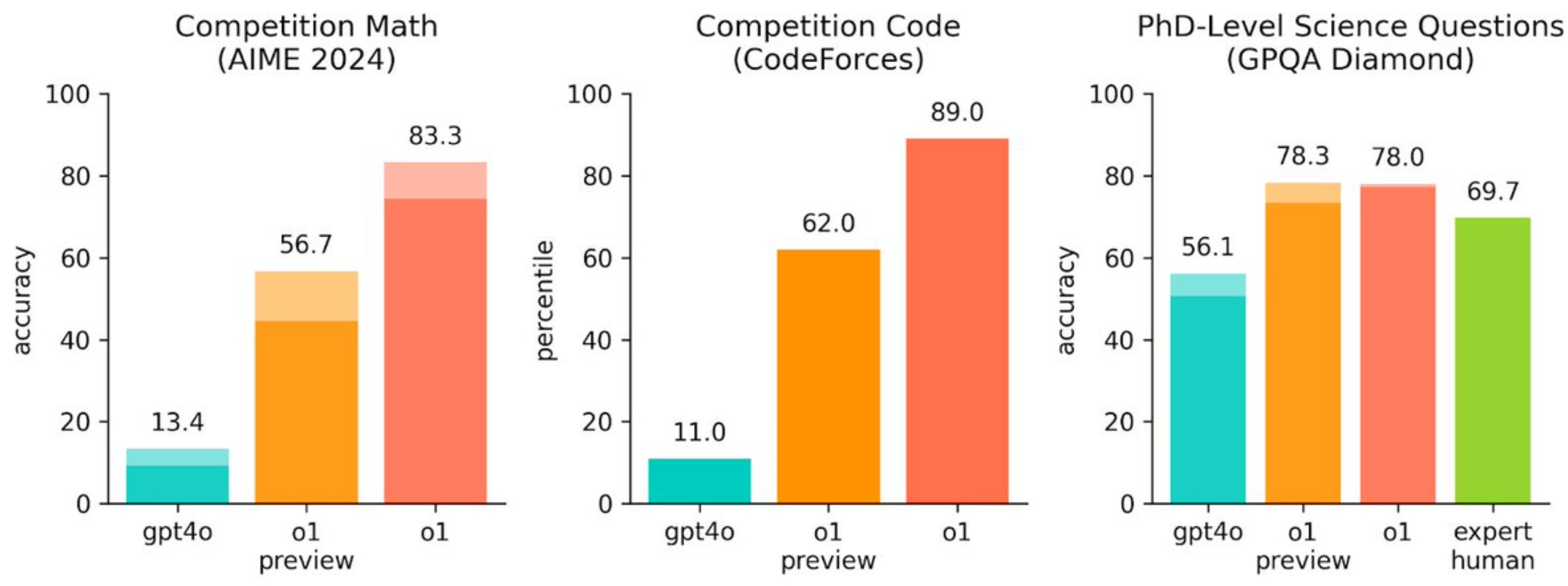
What we should be analyzing is whether a mix of models, with the new one added, is able to solve more difficult problems.
For example, o1-Preview isn't exceptional at writing relative to Sonnet (except for constrained writing and following specific instructions), but it's very good at code generation and reasoning. Therefore, we can create ensembles of these models that push intelligence forward as long as there's improvement in any one area.
Moreover, this new o1 framework introduces a new variable for improved intelligence: time. As the models iterate more, they derive deeper insights and better solutions. Given the consistent momentum in reducing model size and increasing speed, this will be powerful. The o1 API may be initially limited in its usefulness due to time and cost, but there will likely be significant improvements in the ability to create a small and powerful model over the following quarters.
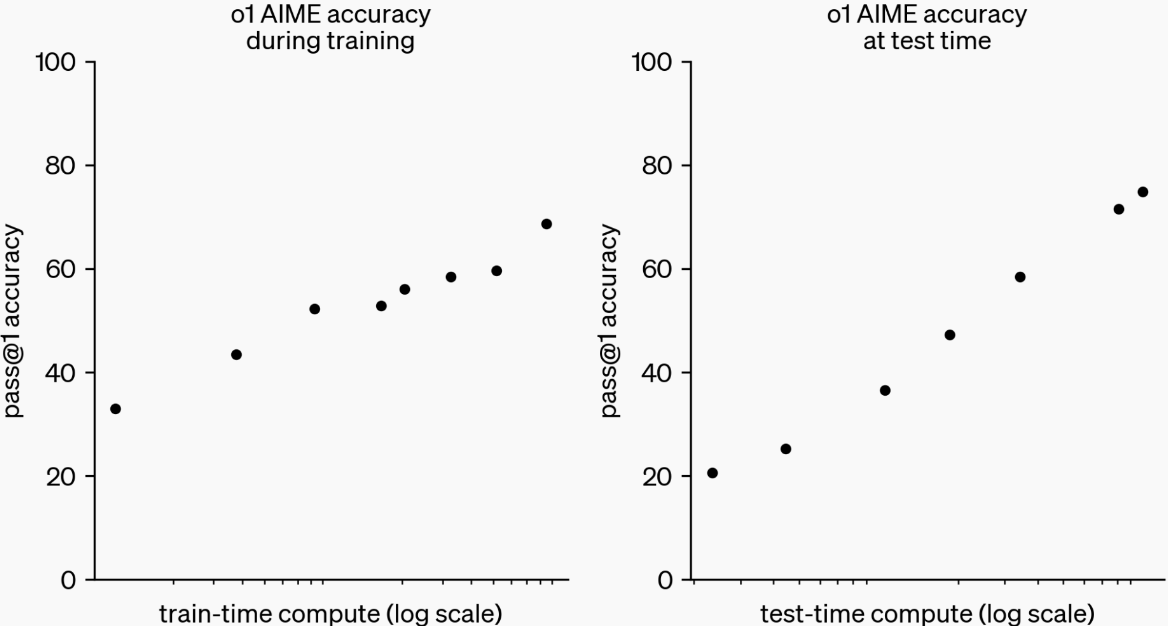
I'm personally impressed by o1-Preview. Overall, I'm significantly more optimistic about LLMs being commercially useful in the near term (1-5 years) than I was a month ago (based on the chance that we've exhausted our abilities to make meaningful progress, given modest updates over 18 months), and I'm slightly more optimistic about the chances that generative AI leads to AGI.
For about 18 months, there was only incremental progress beyond GPT-4. Based on the benchmark results of o1-Preview and o1, it appears we have a step change similar to the step from GPT-3.5 to GPT-4. Orion is likely to add another meaningful step. Skeptics have been claiming that we hit a wall, but this will look increasingly untrue over the next six months.
In areas like code generation (though not code completion), reasoning, math, and applied knowledge in science and law, these o1 models offer substantial improvements. They still have issues and flaws, but the benchmarks and progress in IQ scores, math Olympiad, and coding tests show a clear upward trajectory.
In terms of predictions and extrapolations, we now know with confidence that another new algorithmic improvement (Q*) brings meaningful reasoning advancements. The two open questions are:
We will learn much more based on the release of Orion and Claude 3.5 Opus. We should assess whether, outside of pure reasoning, Orion/Opus have fewer hallucinations and a better world model. We can again update our prediction based on those findings.
Notes:
One side note: I'm somewhat surprised by how much effort was required to develop o1. It took approximately 15 months for 20 of the smartest, most dedicated engineers/scientists to produce o1-Preview, and it isn't an omni model; it doesn't accept file uploads, etc. However, this increase from just one new insight (Q* reasoning) is very significant and suggests we only need a handful of major algorithmic improvements to reach AGI.
As argued in my other article, nothing here suggests there's near-term danger. It's actually very promising that OAI found ways to incorporate safety and alignment work within the CoTs. It seems extremely unlikely that these models are actually conscious, although they can undoubtedly mimic consciousness.
Most philosophers hold a materialist view of consciousness and our ability to reason. The brain is a computer; at the foundational level, neurons fire and create essentially 1s and 0s. Through complex structures, this elegant architecture gives rise to thinking as we understand it.
LLMs should be thought of in the same way. We should look at what LLMs can solve empirically and observe the rate of progress. The emergent ability to solve complex problems is fairly called reasoning, even if the mechanism is just matrix multiplication at its core.
It depends on your definition, but based on most reasonable definitions, no. If we consider Orion as GPT-5 to continue that naming convention, I think some serious people will start suggesting that GPT-6 represents AGI, while others won't be convinced until the equivalent of GPT-10, assuming this pathway can overcome its limitations.

No. o1-Preview and o1-Mini are very useful for code generation. They are great when incorporated (in tandem with Sonnet) into Cursor. And they will multiply the impact engineers can make.
o1 will also be very useful for creating simple personal software and helping automate specific tasks for technically adept non-engineers.
Engineers might spend less time actually writing code as a result of these model improvements, but they will need to simply do more advanced architecture and algorithm work. Engineers will be well-equipped for this and most non-engineers would have no clue how to even start. Real software development is enormously more sophisticated than writing code in a single file and creating a very simple program. AI just increases impact by abstracting and adding efficiency; AI is similar to another abstraction layer, similar to how we've already abstracted from assembly to python.
Engineers will be replaced by AI around the same time that everyone else can be replaced by AI.
With Orion (or perhaps the following generation), I suspect we'll be approaching a point where, in complicated but relatively narrow tasks, third-party application companies (like mine) will have enough power to build tools that are as "intelligent" as sophisticated humans. The application layer can create many advantages:
From there, the key will be context. When intelligence is level, what differentiates humans from AI is that humans possess much more context. So, we'll want to find ways to transfer context to the AI to continue to build efficiencies. By doing all this, we'll likely have something that feels like AGI at the application layer in many commercially important domains well before achieving true AGI. However, Fortune 500 companies are rolling out this technology slowly, and there will be a significant gap between what's possible and the actual adoption curve.
Until we reach true AGI, I generally expect that people who embrace AI will become major force multipliers, while those who ignore AI will find their jobs automated, resulting in a lower market value for their work. This will probably become very apparent around 2027-2028.
In the years/decades after achieving "strong AGI," we may move toward a post-work or work-optional society with tremendous wealth. Alternatively, the rate of progress may slow down more than I expect.
Goal: Determine the differences in speed, hallucinations, quality analysis, and case intelligence across leading OAI models. Also analyze value of additional instructions.
GPT-4o
o1-Preview
O1-Mini
Claude 3.5 Sonnet
Takeaways:
Several more rounds of testing required before release.